Projects
Projects I have been working on.
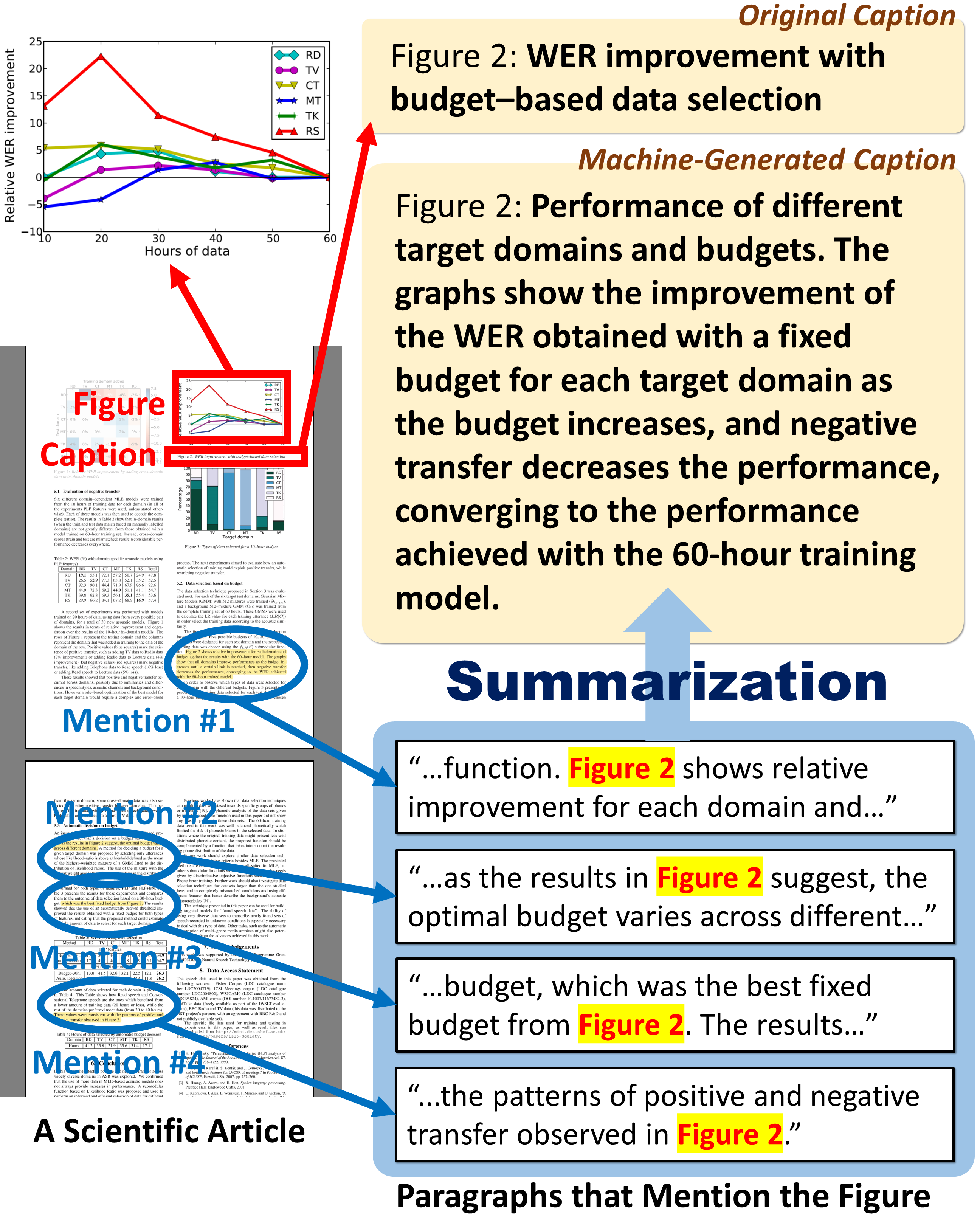
Our project formulates scientific figure captioning as a summarization task, where paragraphs mentioning the figures are summarized to produce informative captions. Through fine-tuning the Pegasus model, we have achieved significant performance improvements compared to vision-to-language models. Furthermore, token alignment experiments have revealed that roughly 75% of the captions can be found in the figure-mentioning paragraphs, confirming the effectiveness of our summarization approach.
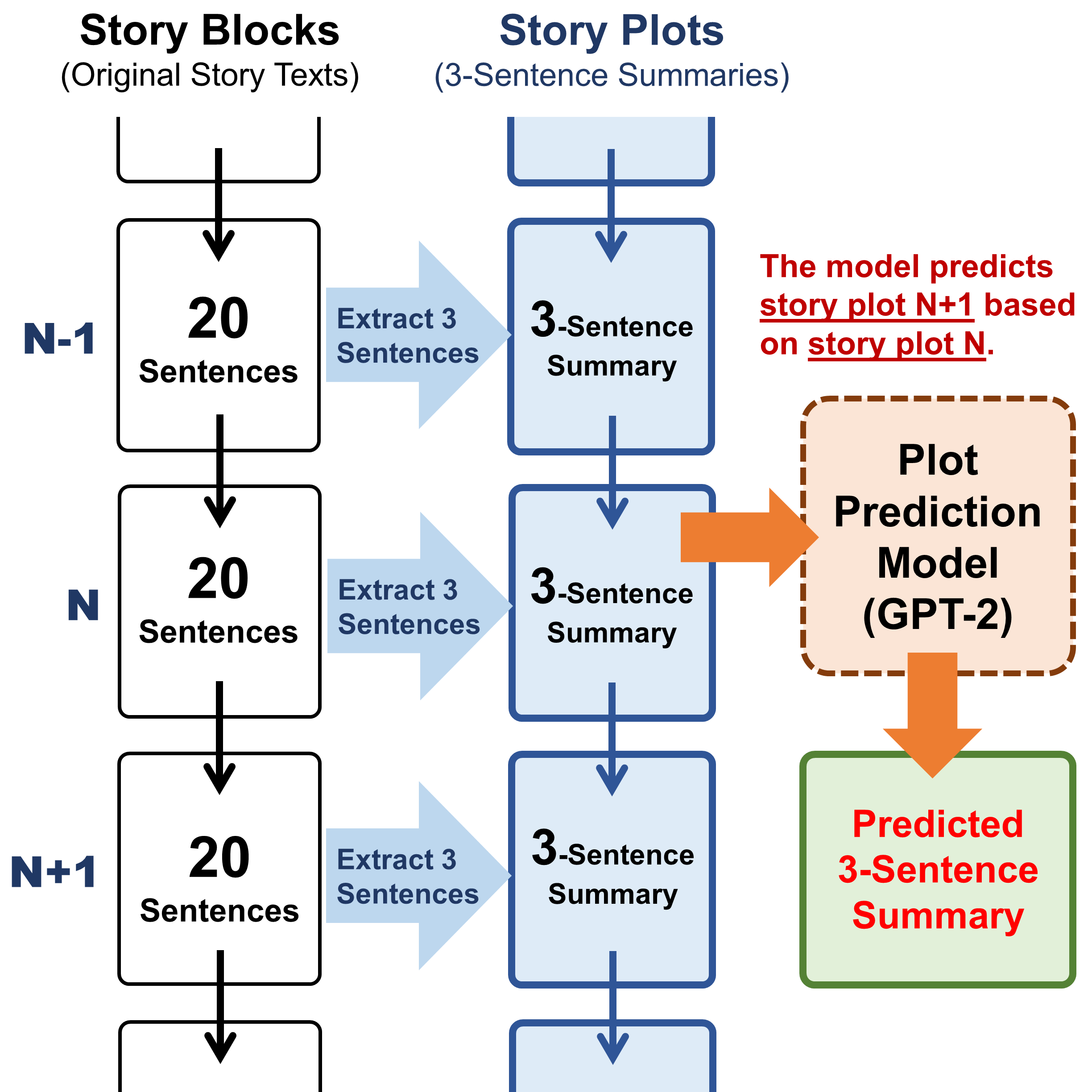
We have developed a system, Semantic Frame Enhanced GPT-2, which generates short descriptions to support novel writing by providing potential future story plots. To evaluate the system's performance, we conducted human evaluations that assessed the quality of the generated story plots and how they were used in a writing task. Despite GPT-3's impressive performance, the proposed model could also make a positive impact on the writing process.
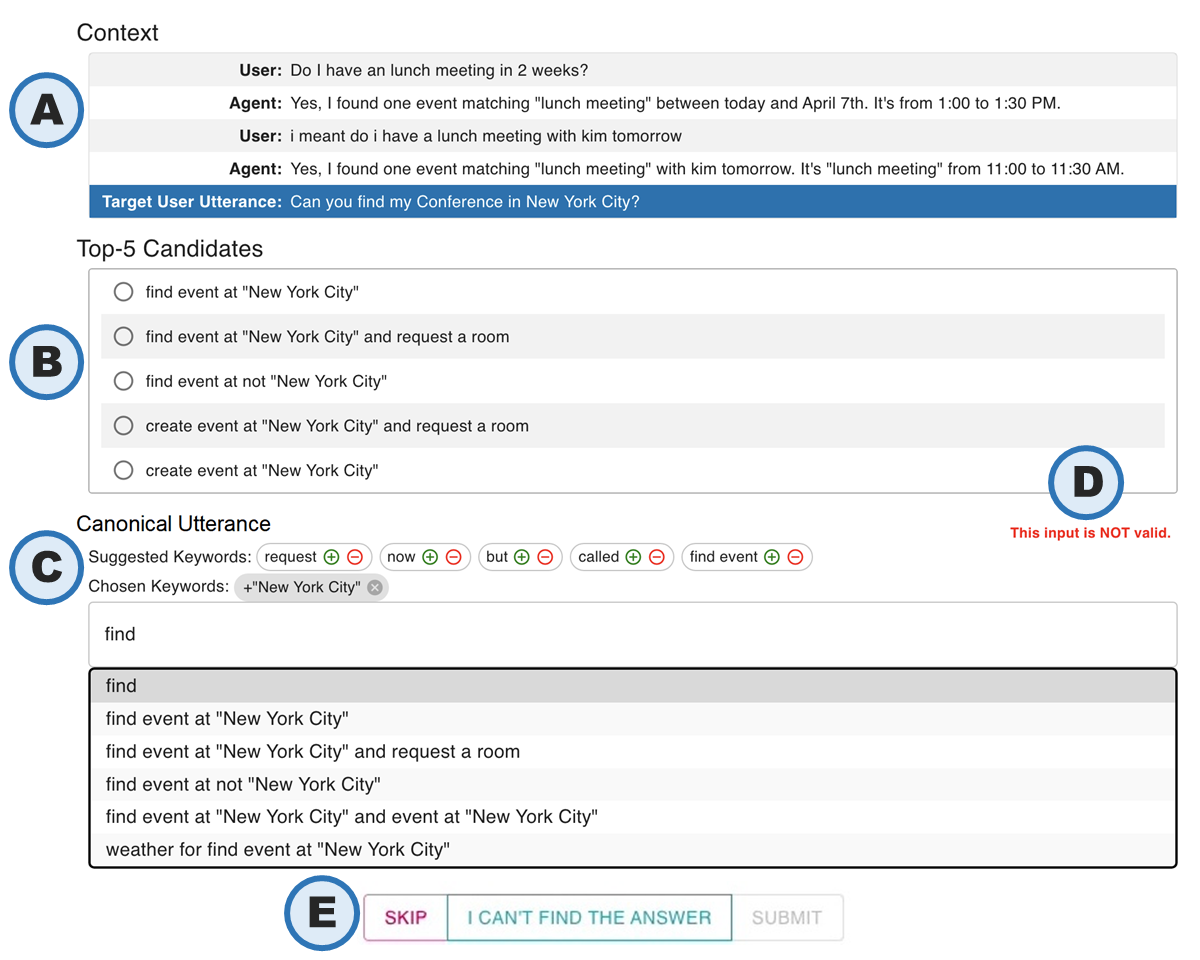
Our paper proposes an AI-powered human-in-the-loop process to collect conversational semantic parsing data efficiently, even with limited data. Our proposed method, guided k-best selection, generates possible candidates, allows users to filter incorrect parses, and asks them to select the correct parse with minimal modifications. We conducted a user study with five annotators and found that combining keyword searching and suggestion enabled fast and accurate annotation.
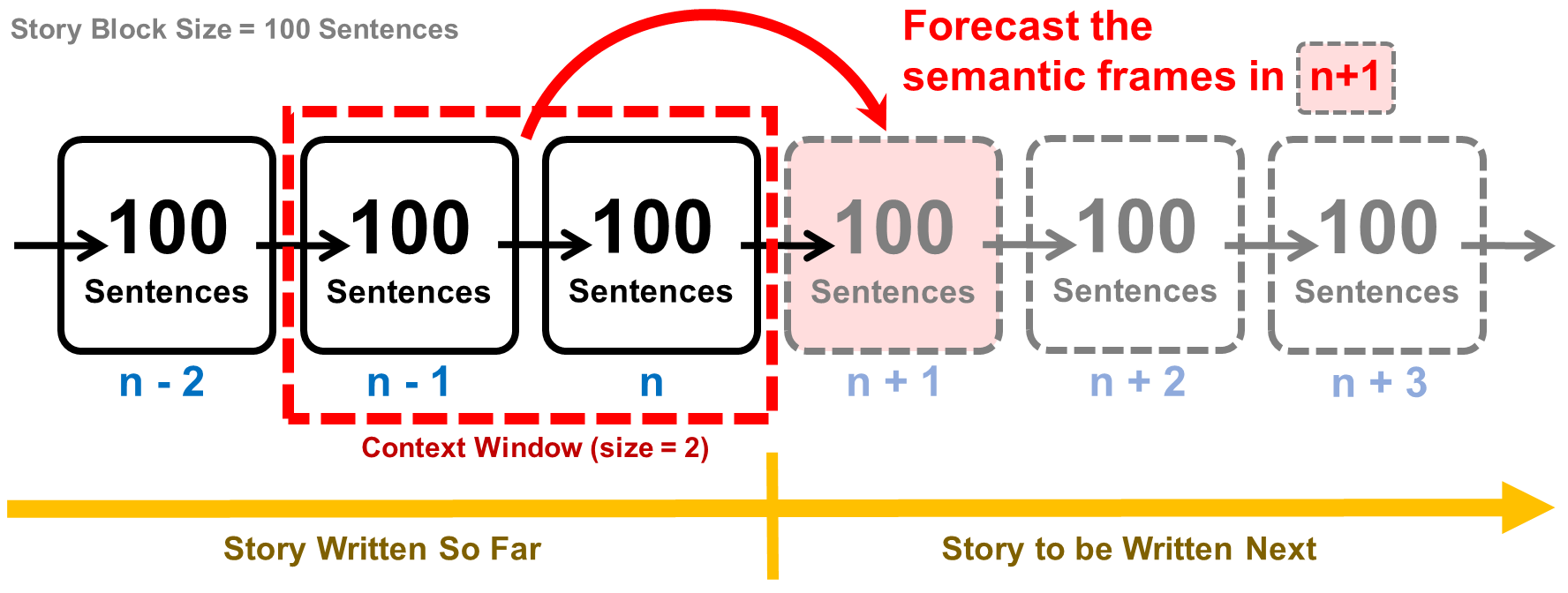
We introduce frame representations to describe story blocks, a story snippet that contains a fixed number of sentences. Using this formulation, we treat a full story as a sequence of story blocks and propose a Semantic Frame Prediction task where the idea is to predict what would happen in the follow-up story using previous information (either in text or in frame representation).
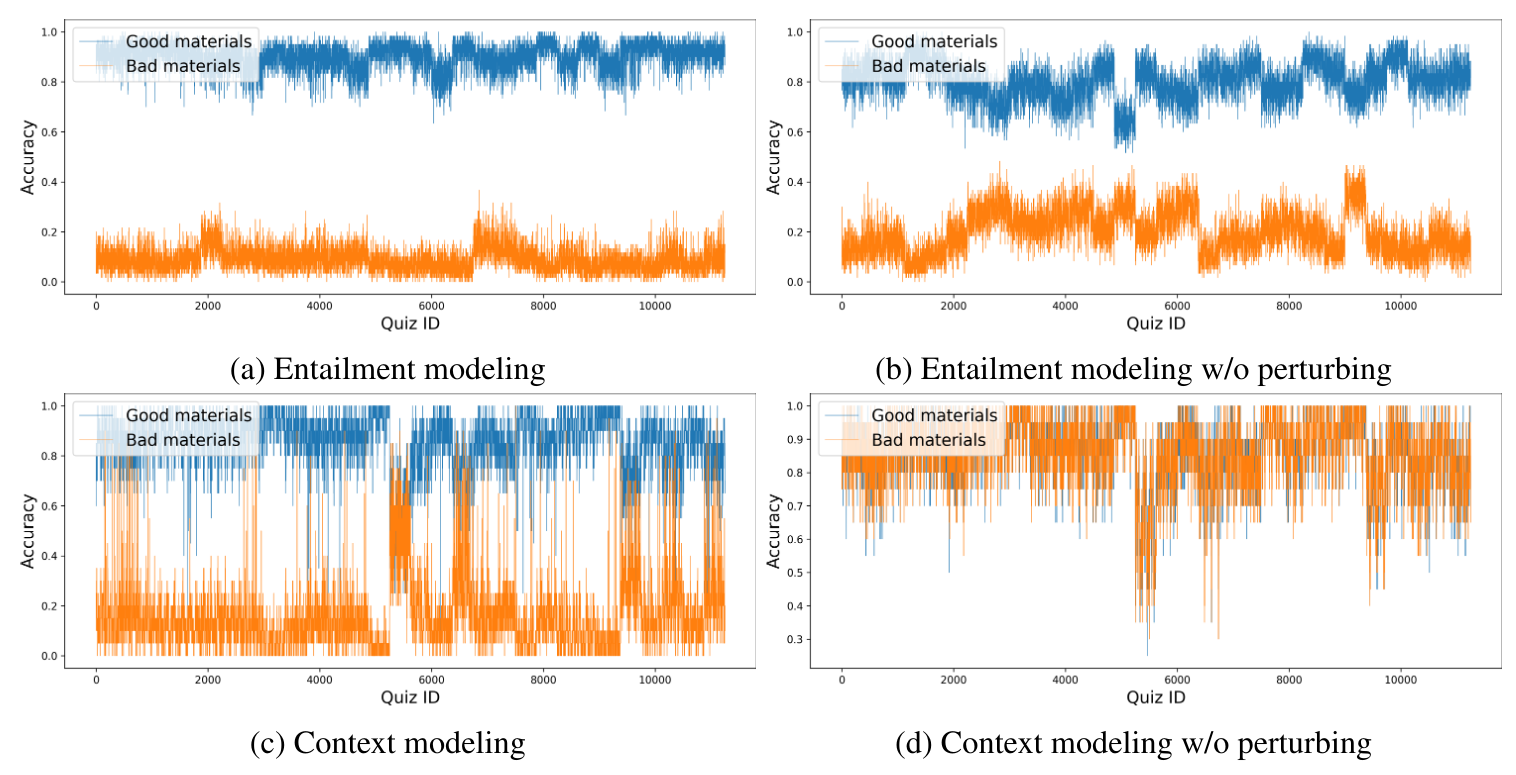
Automatically finding useful learning materials is hard. In this project, we develop a Learner-Like Agent that can mimic learners' behavior. By asking the agent to learn all the materials and test its corresponding performance, we can then find out the good materials.
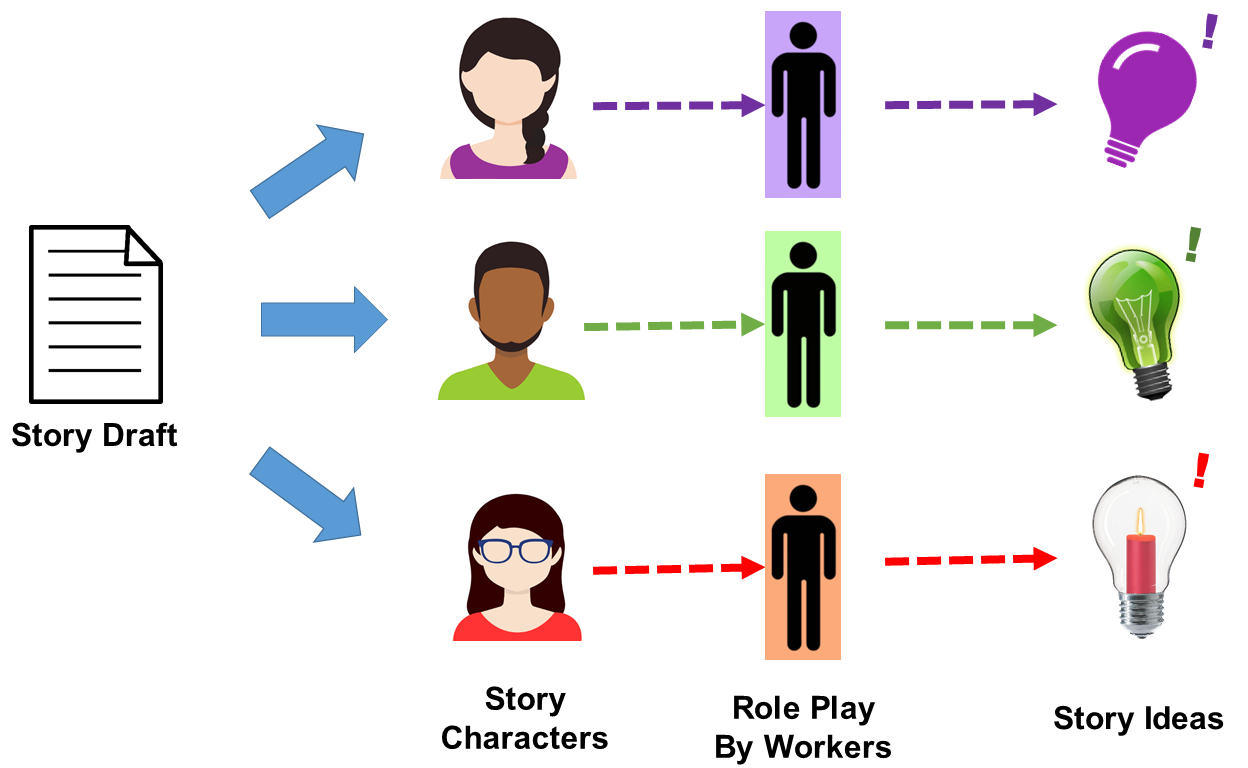
Writing is a complicated task that needs a complex skills. Supporting writing, therefore, is a difficult task for AI since AI is not capable of understanding. In this project, we try to provide various helps for writer by using the power of crowd.
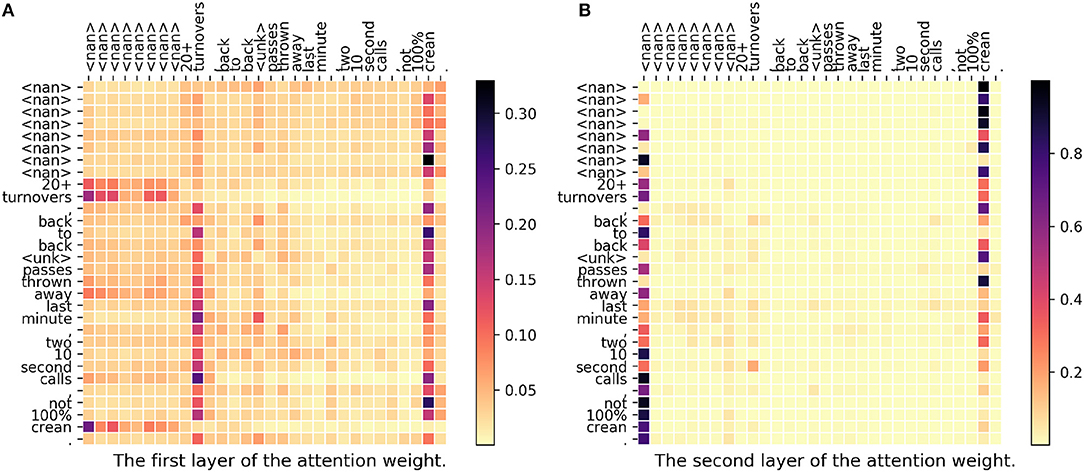
Geographic Information plays an important role on both marketing and event mining, but is usually blocked due to the privacy issues. This project introduces a deep learning architecture taking the attention mechanism, the subword feature, and the location hierarchy structure into account to predict the geographic information for a given post on Twitter.
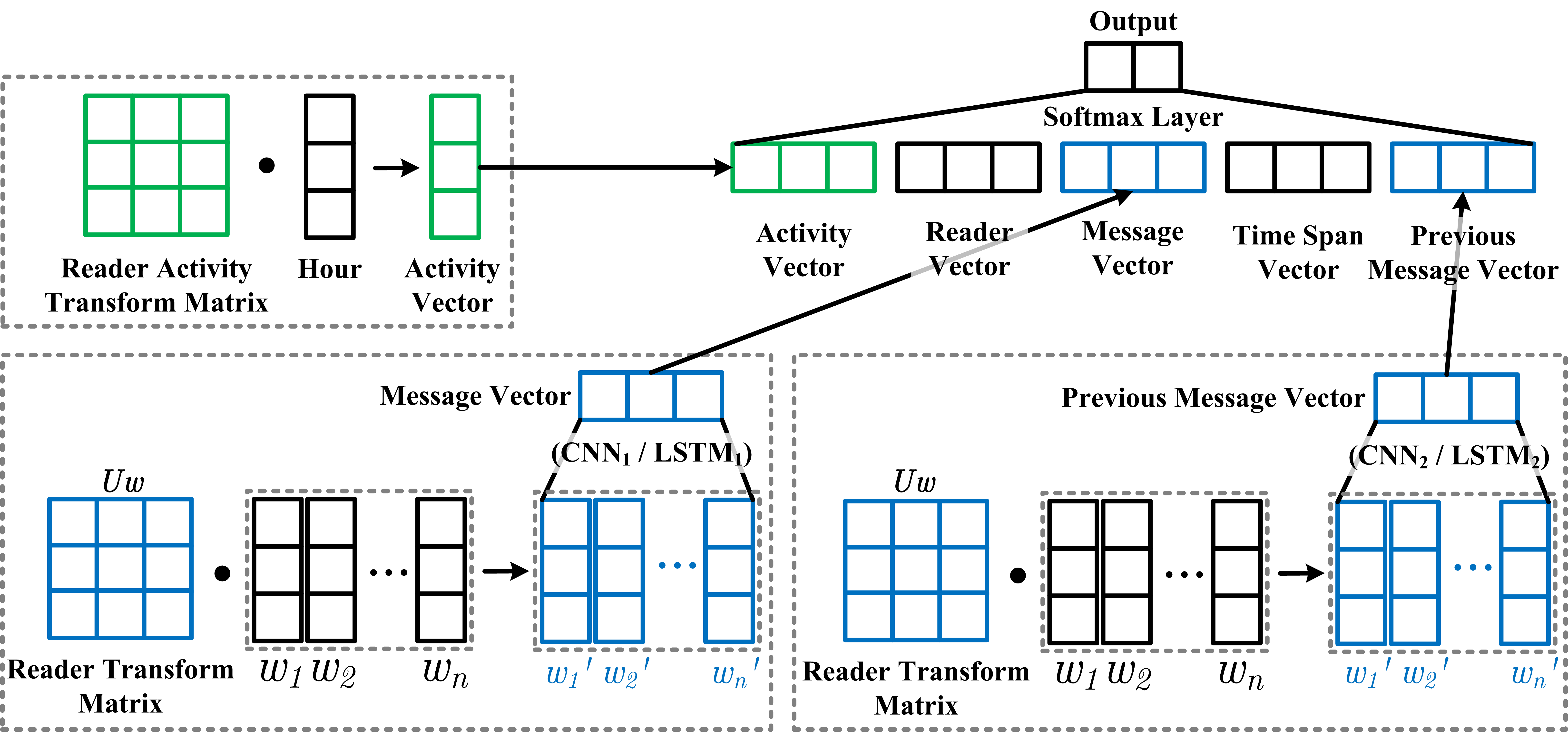
This project aims to predict the response time of a given message sending on the instance message system. This task could be viewed as a measurement of the dialog generation system. A deep learning model integrating conversation and some user-specific information is proposed.
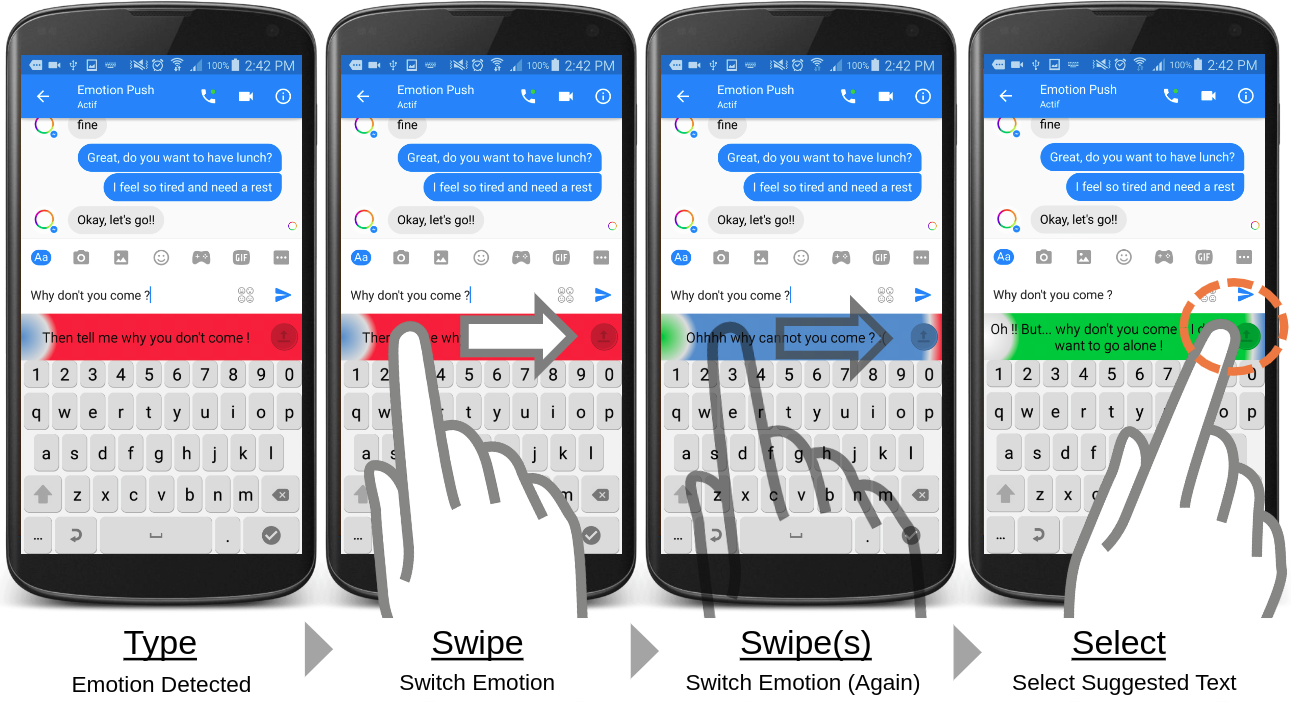
MoodSwipe is a mobile phone keyboard that suggests text messages according to the user-specified emotion. We aim to create a convenient user interface to enjoy the technology of emotion classification and text suggestion, and at the same time to collect labeled data automatically. Two emotion classifier models, CNN and LSTM, and two sentence suggestion models, BM25 and similarity of sentence embedding, are built for MoodSwipe.
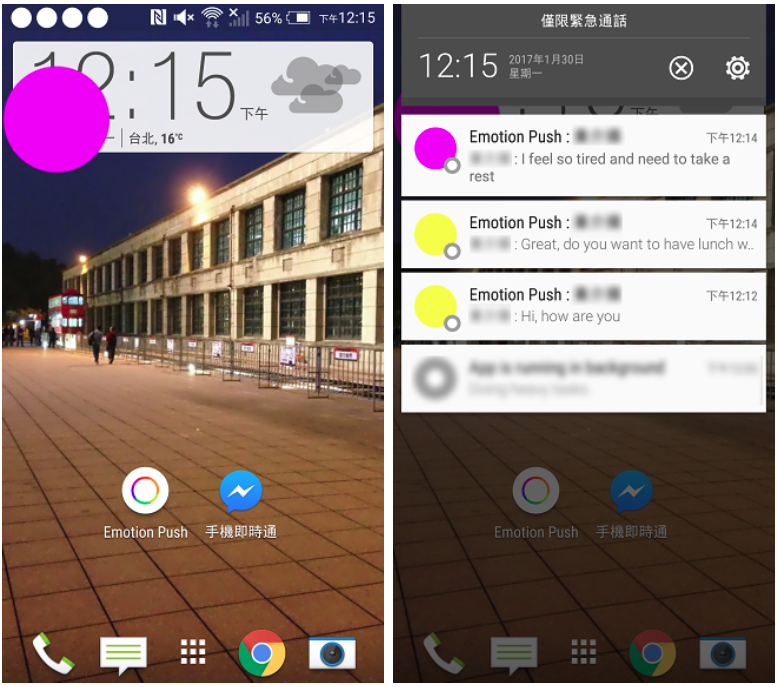
EmotionPush provides a machine-learning-powered system that automatically conveys users’ emotions in messages by color-based emotion cues to bridge the limitation of text-based chatting system in expressing rich emotion.
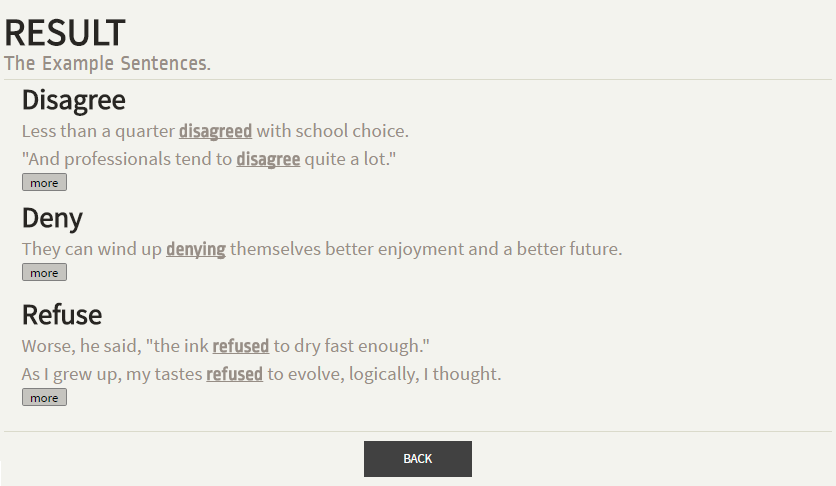
GiveMeExample aims to suggest critical example sentences for language learner to clarify the confusion of synonym. Three main components, the sentence difficulty assessment built by a regression model, the word-sentence fitness estimator built by GMM and BiLSTM, and the heuristic clarification scoring function are introduced to solve this problem. Several websites are built for collecting data and holding evaluation tests.